Garbage Collection in Ruby 3.0
This was written for Ruby 3.0 and is now out-of-date. A more up-to-date version is available here.
Overview
Ruby’s garbage collector code lives in a single file called gc.c. “Garbage collector” is probably not the best term to call it because in addition to garbage collection, code inside gc.c is responsible for memory allocation and management. In other words, the whole lifecycle of an object is managed by code in gc.c.
Data structures
RVALUE struct
The definition for the struct is approximately as follows (I have omitted portions of the code and replaced with ellipses).
typedef struct RVALUE {
union {
...
struct RBasic basic;
struct RObject object;
struct RClass klass;
struct RFloat flonum;
struct RString string;
...
union {
...
} imemo;
struct {
struct RBasic basic;
VALUE v1;
VALUE v2;
VALUE v3;
} values;
} as;
...
} RVALUE;
A Ruby object is represented by an RVALUE struct instance. The RVALUE struct is exactly 40 bytes in size (on systems with 8 byte pointers). These struct instances live in 40 byte slots in a (generally 16KB) page. These pages exist as a linked list inside a heap.
The RVALUE struct can represent any Ruby object using a union of all the types for Ruby objects (such as RObject, RString, RRegexp, RFloat, etc.). It also contains imemo, which is a union of internal types that are not represented by Ruby objects. imemo includes types such as rb_iseq_t which are instruction sequences used to hold the instructions for Ruby code (like a method or a block).
We can use the values struct inside to initialize a generic RVALUE. This struct contains an RBasic struct, which is 16 bytes and contains information about the type of the current object and so we can use the remaining 24 bytes for data (VALUE is a type definition for an unsigned long). The 24 bytes of data is used differently for different types. For example, a short string has the characters directly embedded while a longer string utilizes a pointer.
rb_objspace_t struct
The rb_objspace_t struct contains all the information about the garbage collector, including pointers to the heaps and the state of the garbage collector.
The instance of rb_objspace_t can be accessed using the rb_objspace macro.
The garbage collector contains two heaps, eden_heap and tomb_heap. The eden heap contains pages containing live objects while the tomb heap contains pages without live objects, which can then get recycled and moved back to the eden heap. The pages in the tomb heap may also be freed to release memory back to the system.
Heap page
The heap is divided up into pages, with each page at 16KB. These pages are further divided up into slots, where each slot holds one RVALUE. When we run out of pages, we malloc another page and add it to the list of pages. We free pages when we have too many empty pages (this can happen when a GC run sweeps all the live objects on a page).
Creating objects
The rb_wb_unprotected_newobj_of and rb_wb_protected_newobj_of are the public functions used to create new objects. I’ll talk about the difference between these two functions later. In other Ruby source files, the macros NEWOBJ_OF and RB_NEWOBJ_OF are used to create objects. An example of this being used is in numeric.c in rb_float_new_in_heap that creates a new floating point number.
newobj_of function
The newobj_of function allocates and initializes a new object (i.e. slot) on the heap.
If we are not in a GC run, the GC is not stressful (when the GC is stressful, it will attempt to run garbage collection at every possible point), and there is a free slot available in the page we are using, then we can directly pop this free slot from the linked list and initialize the object in it.
However, if the conditions are not satisfied, we run newobj_slowpath, which tries to use the next free page and then fetch a free slot from this new page (this is done in heap_get_freeobj). However, this would not work if we run out of pages, so we call heap_prepare and run garbage collection to try to free up space. If we still do not have space, then we add a new page to the heap (by calling heap_increment).
Incremental marking occurs during object creation in newobj_slowpath (incremental marking is explained later on). To be specific, it happens in heap_get_freeobj -> heap_get_freeobj_from_next_freepage -> heap_prepare -> gc_marks_continue -> gc_marks_step.
Garbage collection lifecycle
The garbage collector is split into two phases: it first marks, then sweeps (and a third compaction phase that is currently in development).
In the marking phase, living objects are marked in a bitmap. Then, during the sweeping phase, the unmarked slots are freed and recycled in the free list.
As you may know, MRI Ruby is single threaded, and the garbage collector is no different. This is known as a “stop-the-world” garbage collector. This can cause long pauses in the Ruby code when the garbage collector is running, especially in a large Rails app, for example. Ruby solves this problem using two solutions, incrementally marking objects, and using a generational garbage collector, both described in greater detail below.
Marking phase
The marking phase traverses live Ruby objects by recursively marking children of live Ruby objects starting from root objects. Objects are marked using three colors: white, grey, and black. At a high level, the tri-color marking algorithm works as follows:
- All objects are initially white.
- Mark root objects as grey.
- While there is another object O that is grey:
- Mark O as black.
- Mark every child C of O as grey.
At the end of the marking phase, there are only black and white objects and all live objects that are white are dead and can be swept.
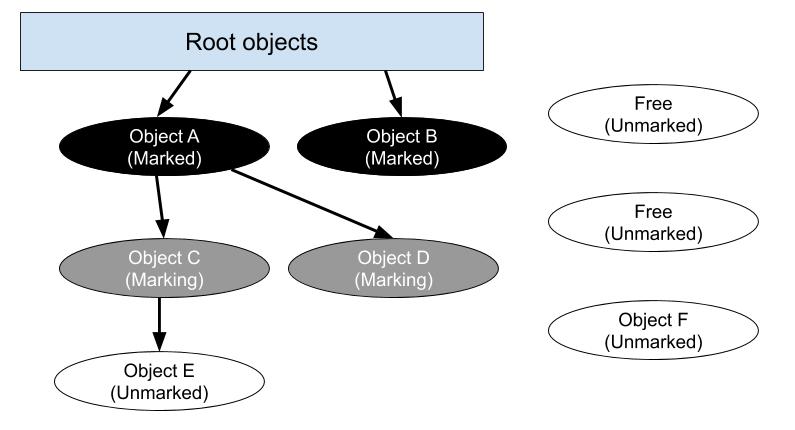
In the figure above, objects A and B are marked black, while objects C and D are grey, and object E has not yet been marked. We also have object F that is not referenced by any Ruby objects, so won’t be marked and will be reclaimed during the sweeping phase. We also two free slots that are currently unused.
Generational garbage collector
Generational garbage collectors are based on the weak generational hypothesis theory, which states that objects often die young, and objects that have been alive for a long time are likely to remain alive. Generational garbage collectors keep track of the number of garbage collection cycles a particular object has survived, and when this number exceeds a threshold, the object is marked as an old object. To take advantage of this property to improve performance, we have two types of marking: minor GC and major GC.
Minor GC runs mark only the young objects, thus it can run faster by skipping old objects.
Major GC runs mark both the young and old objects, thus it can free more memory.
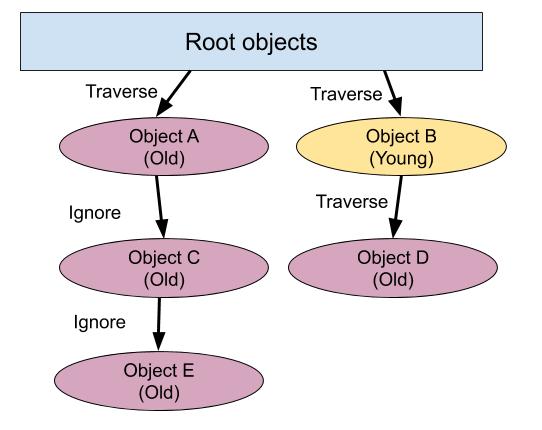
In the figure above, when we are in a minor GC, none of the descendants of object A will be traversed during marking.
The number of generations an object has survived is stored in the flags in the RBasic struct. We can get the age of the object using RVALUE_FLAGS_AGE and RVALUE_OLD_P_RAW which returns the age and whether an object is old, respectively.
Remember set and write barrier
What if we added a child (that is a young object) to an old object? Then during minor GC the young object would not be marked and thus will be swept. This is a really bad bug.
Here’s a diagram to illustrate the bug.
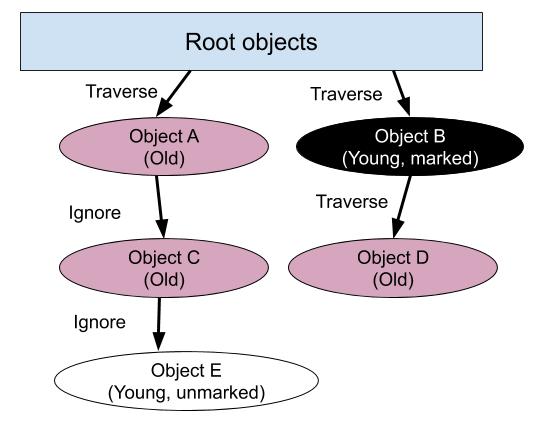
In the diagram above, since objects A and C are old, they are not traversed during marking. However, object E is a young descendant of object C. Since object E is never marked, it will be swept.
To solve this issue, we introduce the concept of a write barrier. A write barrier is essentially a “callback” to let the garbage collector know whenever an object is written to. When the write barrier is called, the child (young object) is placed in a special list called the remember set. This remember set is marked during minor GC runs.
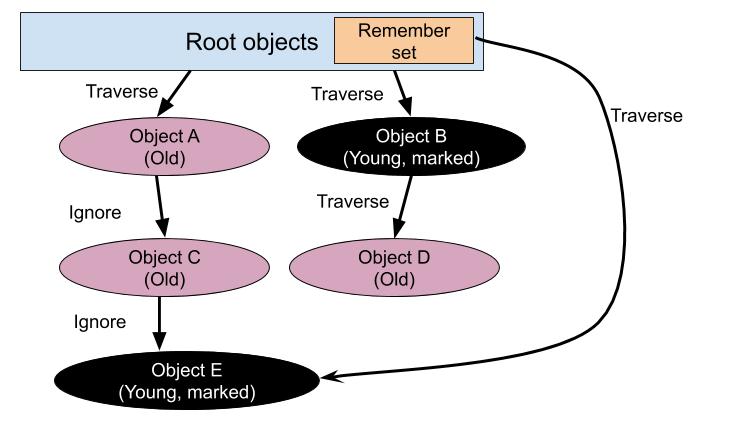
Generational garbage collection was introduced in Ruby 2.1. To preserve backward compatibility with old C-extensions, Ruby supports a write barrier unprotect operation. When we write barrier unprotect an object, we mark the object as shady and keep it in the remember set. Shady objects are not allowed to be promoted to old generation, so thus shady objects will always be marked during both minor and major GC.
If you’re interested in more details, Koichi Sasada has an excellent paper written about implementing gradual write barriers.
Incremental marking
Ruby 2.2 introduced the incremental garbage collector. Koichi Sasada has an execellent article explaining how the incremental garbage collector works, I will attempt to summarize it below.
The main idea of incremental marking is to not run the marking phase all at once, but divide it into chunks that can be interleaved with the execution of Ruby code. Since Ruby has a stop-the-world GC (i.e. no Ruby code can run while the GC is running), so splitting the marking phase can significantly reduce the stutter caused by GC execution.
Incremental marking marks only a certain number of slots before completing, so during the execution of Ruby code, some objects may be marked black, some may be marked grey, while some may not have been marked yet at all. The number of slots that is incrementally marked is stored in the step_slots field.
Incremental marking only occurs during major GC runs, as we can see in gc_marks (the code completes marking if we are not incrementally marking).
Write barrier, part II
A corner case that we run into during incremental marking is when a young object is added as a child of an old object, so during a minor GC run, this young object is not marked as live, and thus is swept even though it should not be. This is a very similar issue we saw while implementing generational garbage collection, so we can take advantage of the write barrier again.
In this case, if the write barrier detects that we are adding a child to a black object, then the child will be marked as grey.
Sweeping phase
The sweeping phase iterates over the slots in the pages and reclaims slots not marked in the marking phase by appending them to the linked list of free slots.
Compaction phase
As of the time of writing, compaction is a work-in-progress. Compaction is not yet automatic. It can be manually triggered by calling
GC.compact.
As our Ruby program allocates and deallocates objects, it’s inevitable that our heap memory (i.e. slots inside pages) have “holes”, as some objects are longer lived while others are swept. This is known as fragmentation, where we have many free slots between live objects. Fragmentation increases memory usage as it prevents pages that are mostly empty from being freed. Having a lot of pages also slows down both the garbage collector and regular execution of code. It’s pretty obvious that it would slow down the garbage collector, as both the marking and sweeping phases iterate over the pages. This could also slow down the execution of Ruby code as CPU caches become less effective because the caches would be caching more of empty slots rather than useful data. If we also had some way of moving related objects closer to one another, we might also be able to improve performance by increasing cache hits (this is not currently being done in the Ruby GC).
The compaction phase attempts to solve this problem by moving Ruby objects on the heap.
Parts of this section is adapted from Aaron Patterson’s (original author of compaction) feature proposal.
C extension
As you may know, some Ruby gems are written partially in C for performance reasons, these are known as C extensions. These C extensions sometimes hold pointers to Ruby objects. If we moved these objects, the C extension would point to the wrong object.
To allow backward compatibility, objects can be pinned (pinned objects are marked in a bitmap). A pinned object is not allowed to be moved. The default public API function for marking Ruby objects, rb_gc_mark, marks and pins the objects. Another function, rb_gc_mark_movable, was introduced for C extensions that support compaction (the C extension registers a callback that is executed when an object is moved).
Algorithm
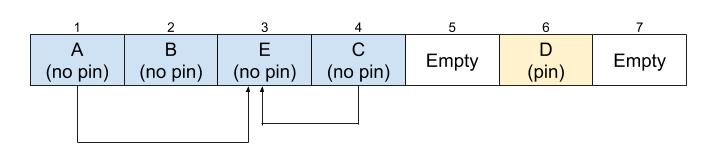
To illustrate the compaction algorithm, I will be using the following heap as an example. In the example, objects A and C hold a reference to object E.
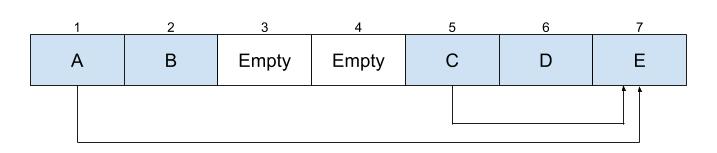
Step one: Major GC
Before we can do compaction, we must first do a major GC run. This will set up the pin bitmap described above.
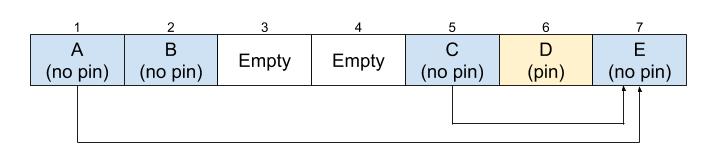
Step two: Move objects
The compactor uses a two finger compaction algorithm. As the name suggests, we have two fingers, one finger that moves from left to the right called the “free” finger and another finger that moves from the right to the left called the “scan” finger. The “free” finger finds the next empty slot and the “scan” finger finds the next object. As long as the “free” and “scan” fingers have not met, we swap these two objects (of course, we cannot move pinned objects) and leave a marker (a T_MOVED object) to say that we moved the object from “scan” to “free”. We repeat until the “free” and “scan” fingers have met.
In Ruby pseudocode, it looks a little like the following (of course, the real version is implemented in C). Assume that heap is an array containing all the objects. Also assume that is_empty? and can_move? are functions that returns true if the slot is empty and the slot can move (i.e. not pinned), respectively, and otherwise returns false.
free_idx = 0
scan_idx = heap.length - 1
while free_idx < scan_idx
# Move "free" finger right until we reach a empty slot
while free_idx < scan_idx && !is_empty?(heap[free_idx])
free_idx += 1
end
# Move "scan" finger left until we reach a non-empty slot
while free_idx < scan_idx && is_empty?(heap[scan_idx])
scan_idx -= 1
end
# If we can move `scan` to `free`
if free_idx < scan_idx && can_move?(scan)
# Move `scan` to `free`
heap[free_idx] = heap[scan_idx]
# Marker at scan_idx pointing to free_idx
heap[scan_idx] = T_MOVED.new(free_idx)
end
end
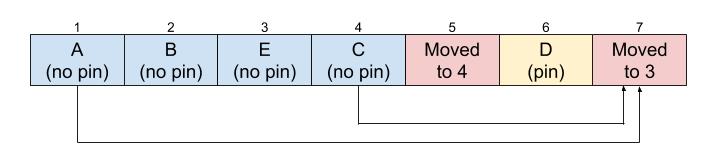
Step three: update references
After compaction, we traverse all the objects in the heap and update their references (pointers) that have moved (the pointers point to a T_MOVED) and update the pointer to point directly to the moved object.
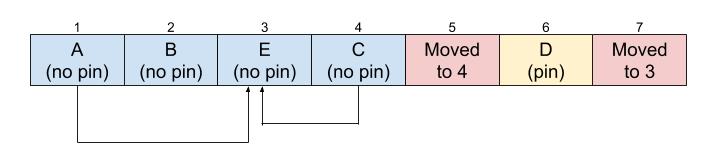
Step four: freeing T_MOVED slots
At this point, there should not be anything pointing to the original locations of moved objects (there would be a critical bug if there were!), so we can free these slots and reuse the memory. The RMoved struct is a linked list that we can traverse and free.
Conclusion
That’s all folks! To recap, in this blog post, you were introduced to some of the important data structures in the garbage collector, you saw how Ruby objects are represented and created internally, and you also saw how the marking, sweeping, and compaction algorithms work.