A Rubyist's Walk Along the C-side (Part 7): TypedData Objects
This is an article in a multi-part series called “A Rubyist’s Walk Along the C-side”
In the previous article, we saw how to define and use Ruby classes and modules through the C API. However, we might have noticed that for pretty much every operation, we needed to call into Ruby (e.g. reading and writing instance variables, calling methods, etc.). This, in many ways, defeats the purpose of writing a C extension since one of the goals of writing C extensions is to improve performance by relying on Ruby less. Spoiler alert: in a future article, we’ll use benchmarks to show that writing C extensions this way might actually be SLOWER than writing it in Ruby.
What are TypedData objects?
TypedData objects allow the C extension developer to store their own C struct in objects. Unlike instance variables where the values have to be valid Ruby objects, anything can be placed in this struct.
It’s important to note that when we pass a TypedData object back to Ruby, it will look just like any other Ruby object. In other words, we can still do operations like access instance variables and call methods on a TypedData object.
Memory layout
Let’s compare how the internal memory structure of TypedData objects differs from regular Ruby objects.
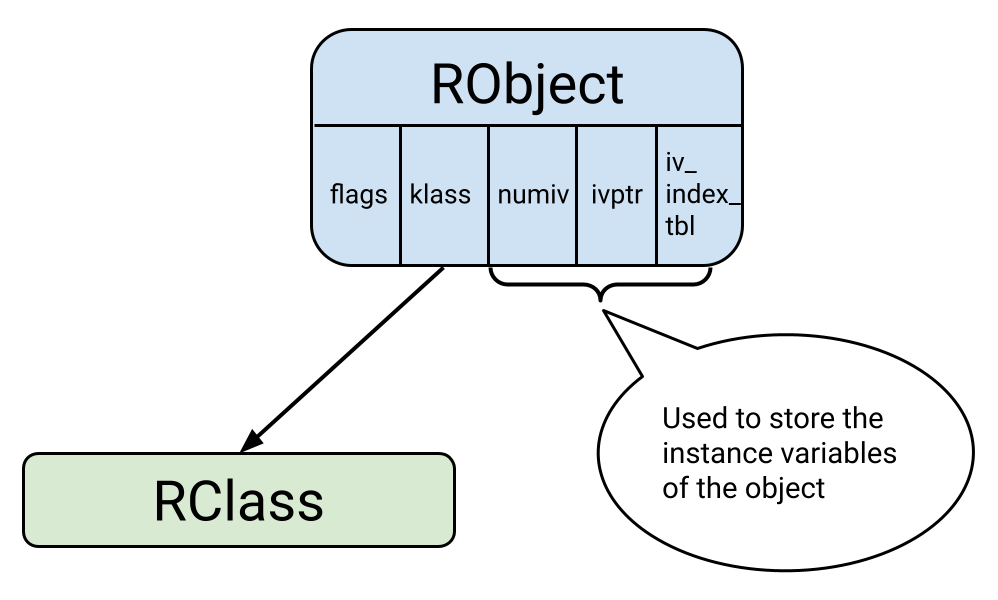
Let’s first look at how regular Ruby objects are represented internally. Ruby has many built-in types (e.g. Class, Hash, Object, etc.). Every type requires allocating an RVALUE, which is a 40 byte region of memory. The RVALUE in the diagram below is the RObject structure. All RVALUEs have their first 16 bytes reserved: the first 8 bytes is for flags which contains metadata about the object, followed by klass which points to the class of the object. The remaining 24 bytes of the RVALUE is where the type can store its data and is different for every type. If you’re interested in a more detailed explanation of the RVALUE, read this.
RObject
The RObject type is used to represent Ruby objects that are not one of the built-in types. The 24 bytes in the RVALUE are used to store information about its instance variables. This includes three fields:
numiv: The number of instance variables.ivptr: A pointer to all of the instance variables in a C array.iv_index_tbl: A hash table that maps instance variable name to value.
RTypedData
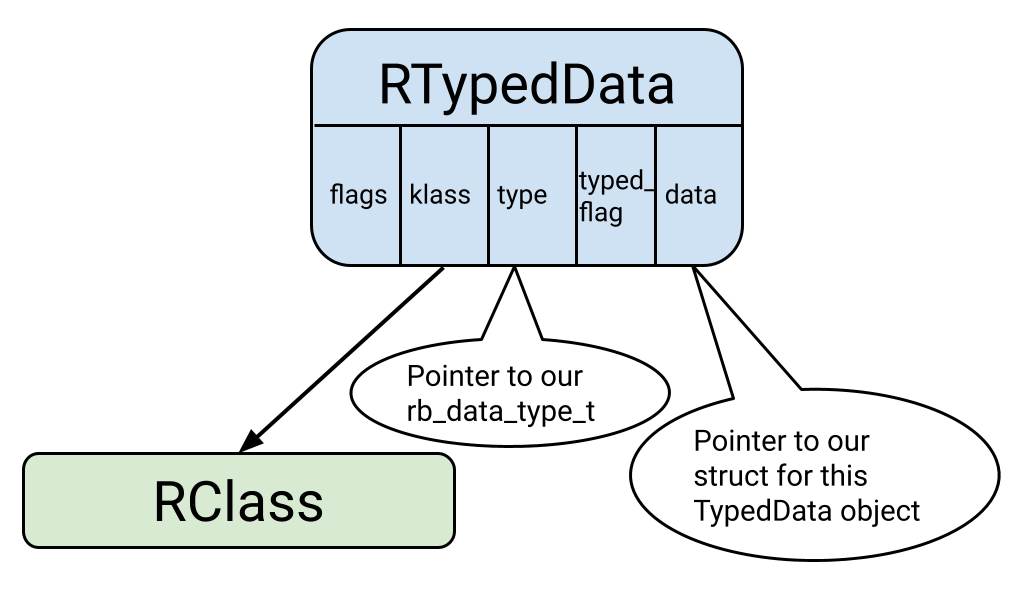
Let’s now look at how TypedData objects are represented internally. The first 16 bytes are the same, with the flags and klass fields. The remaining 24 bytes are very different from the RObject type. The three fields for RTypedData are:
type: This holds a pointer to arb_data_type_tstruct that holds the configuration for the TypedData object. We’ll talk more aboutrb_data_type_tlater.typed_flag: Internal flags for the object.data: A pointer to a region of memory that can contain any data that we want! When we allocate the TypedData object, we pass in a C struct that we want to allocate. The pointer to that allocated C struct is stored here. We’ll see how to allocate TypedData objects soon.
Advantages
As we’ll see in a future article, TypedData objects are fast. The main reason why it’s more performant is that it reads memory directly rather than looking up instance variables from a hash table. Another reason is that with TypedData objects we don’t need to call into Ruby as much, allowing the compiler to perform more optimizations.
Another advantage of TypedData objects is that it will help make the C code cleaner and easier to read because rather than accessing instance variables and calling methods, we can perform C struct accesses and call C functions without ever calling into Ruby.
Disadvantages
The biggest disadvantage of TypedData objects is that we have to manually manage memory. This is difficult to implement correctly and incorrect implementation can have a lot of subtle bugs. Since the data struct can contain any arbitrary data, we have to let Ruby know which Ruby objects we’re holding a reference to. Otherwise, Ruby’s garbage collector may reclaim the object and lead to crashes or undefined behavior (we saw an example of this kind of bug back in part 5). This isn’t a problem when we used instance variables since Ruby handled all of the memory management for us.
There’s also more boilerplate we need to write for a TypedData object, including defining a custom allocator and initializing a rb_data_type_t struct to hold configuration, both of which will be discussed in detail below.
Creating TypedData objects
Defining allocation function
To create TypedData objects, we must define a custom allocation function for our class. The allocation function is the function used to create the object and allocate memory for it. The allocation function is called before the constructor (i.e. initialize method). You can sort of think of an allocation function as overriding the new class method for the class.
To define an allocation function, we can use the rb_define_alloc_func function. It accepts two arguments and returns nothing:
klass: The class to define the allocation function on.func: The allocation function. We’ll discuss this in more detail below.
// Function prototype for rb_define_alloc_func
void rb_define_alloc_func(VALUE klass, VALUE (*func)(VALUE));
// Example of defining an allocation function for class Foo
// First, we define an allocation function
static VALUE foo_allocate(VALUE klass)
{
VALUE obj;
// Allocator implementation goes here
// We'll discuss this in more detail below
return obj;
}
// Init function that initializes our C extension
void Init_test(void)
{
// Create class Foo
VALUE cFoo = rb_define_class("Foo", rb_cObject);
// Define allocation function for class Foo
rb_define_alloc_func(cFoo, foo_allocate);
}
The implementation function (foo_allocate in this example) is where we will create a TypedData object instead of a traditional Ruby object. The allocation function must accept one argument and return the allocated object:
klass: The class of the object to allocate. This is usually the class that we defined this allocator on but will differ when an instance of a subclass is created.
rb_data_type_t struct
We need to initialize a rb_data_type_t struct to hold information about our TypedData object. Usually, this is stored as a global C constant. This must be alive for at least as long as the object itself, so it is a good idea to not allocate this as a local variable on the C stack. Initializing this struct is fairly complex, so it will be discussed in more detail later.
const rb_data_type_t foo_data_type = {
// Initialization values goes here
};
Data struct
We also need to define a C struct to hold data for the object. In the example below, we define a struct called foo_t that has two VALUE attributes (that could hold Ruby objects), one void pointer for a buffer, and a size_t to store the size of the buffer.
typedef struct foo {
VALUE obj_one;
VALUE obj_two;
void *my_buffer;
size_t buffer_size;
} foo_t;
Creating a TypedData object
To create a TypedData object, we can use the TypedData_Make_Struct macro. This macro accepts four arguments and returns the TypedData object that was created:
klass: The class to create an instance of.type: The data struct to allocate for this object.data_type: Therb_data_type_tfor this object (rb_data_type_twill be discussed in further detail below, but you can think of it as essentially holding the “configuration” of the TypedData object).sval: A pointer to thetypethat will be updated to point to the allocated data struct.
// Since this is a macro, there is no function prototype
#define TypedData_Make_Struct(klass, type, data_type, sval)
// Example creating a TypedData object
// foo_data_type is usually be a global C variable
const rb_data_type_t foo_data_type = {
// Initialization values goes here
// We'll discuss this in more detail below
};
static VALUE foo_allocate(VALUE klass)
{
// foo will be set to point to the struct of the new object
// at foo_obj
foo_t *foo;
// obj will be a TypedData object with memory allocated
// for foo_t
VALUE obj = TypedData_Make_Struct(klass, foo_t,
&foo_data_type, foo);
// At this point we can write to foo
foo->obj_one = rb_str_new_cstr("Hello world!");
foo->obj_two = rb_ary_new();
foo->my_buffer = malloc(100);
foo->buffer_size = 100;
// Return the allocated TypedData object
return obj;
}
rb_data_type_t struct
The heart of a TypedData object is the rb_data_type_t struct. This struct holds all the information Ruby needs to know about the object. A (simplified) definition of the struct is as follows. You can find the full definition of this struct in the Ruby source.
typedef struct rb_data_type_struct {
const char *wrap_struct_name;
struct {
RUBY_DATA_FUNC dmark;
RUBY_DATA_FUNC dfree;
size_t (*dsize)(const void *);
RUBY_DATA_FUNC dcompact;
} function;
VALUE flags;
} rb_data_type_t;
Although not shown, there are some padding and reserved fields in this struct that we don’t use, and those must be zero’d. An easy way to initialize this struct is to use the C struct initialization syntax since it guarantees that all uninitialized attributes are zero’d. The following example shows an example initialization of the rb_data_type_t struct. Don’t worry if it looks overwhelming, we’ll go into each attribute in more detail below.
const rb_data_type_t foo_data_type = {
.wrap_struct_name = "foo",
.function = {
.dmark = foo_mark,
.dfree = foo_free,
.dsize = foo_memsize,
.dcompact = foo_compact
},
.flags = RUBY_TYPED_FREE_IMMEDIATELY
};
wrap_struct_name
This is a C string name we give for our TypedData object. This name is used for debugging and statistics purposes. Although there are no requirements for this name (it just has to be a valid C string that’s null-terminated), it is a good idea to give it an informative and unique name to make it easy for yourself and other developers to identify the object.
ObjectSpace.dump
One use case for wrap_struct_name is the ObjectSpace.dump method. This method takes in an object and dumps internal data about it as a JSON string.
In the following example Ruby script, we create an instance of Foo which is a TypedData object.
# Load our C extension
require_relative "ext/test"
# Load the objspace library
require "objspace"
# obj is a TypedData object of class Foo
obj = Foo.new
pp ObjectSpace.dump(obj)
# {:address=>"0x7fb6300719d8",
# :type=>"DATA",
# :class=>"0x7fb6300805a0",
# :struct=>"foo",
# :memsize=>172}
Let’s discuss the output of ObjectSpace.dump. As you can see, it’s a JSON string. The keys are as follows:
address: The memory address that this object is located.type: The internal data type of the object. This is a TypedData object so the type isDATA. If we passed in a hash object instead thentypewould beHASH, for example.class: The memory address of the class of this object (which would be classFooin this case).struct: Here we see the name we set for our TypedData object inwrap_struct_name.memsize: The approximate memory usage of this object. This is the value returned by thedsizefunction. We’ll discuss this in more detail below.
The ObjectSpace.dump and ObjectSpace.dump_all (which dumps all objects in the current Ruby process) methods are useful for debugging and profiling, which will be discussed in further detail in a future article.
dmark
This is the marking function for our TypedData object. Since the data struct of the TypedData object could hold anything, this function is used to tell Ruby which objects are held by this object so Ruby’s garbage collector won’t reclaim them. Since this function is called during garbage collection, it’s important to not allocate any Ruby objects in this function.
To mark an object, use one of the following functions:
rb_gc_mark: This is the easiest one to use. It will mark an object and pin it. Pinning means that the object will not move, so we don’t have to worry about the compactor moving the object.rb_gc_mark_movable: If we do want to support compaction (which brings benefits like better copy-on-write performance), use this instead ofrb_gc_mark. Note that thedcompactfunction must be implemented if we use this.
Both rb_gc_mark and rb_gc_mark_movable are very simple to use, their function prototypes are the same. They both accept one argument and don’t return anything:
ptr: The object to mark.
// Function prototypes for rb_gc_mark and rb_gc_mark_movable
void rb_gc_mark(VALUE ptr);
void rb_gc_mark_movable(VALUE ptr);
Now, to implement the dmark function, it must accept one argument and return nothing:
ptr: Avoidpointer to the data struct of the object. We can cast this to the struct type of the object.
// Example defining the mark function
static void foo_mark(void *ptr)
{
foo_t *foo = (foo_t *)ptr;
// Mark obj_one and obj_two because they point to Ruby objects
// We use rb_gc_mark_movable here because we want to support
// compaction
// Replace rb_gc_mark_movable with rb_gc_mark if you don't
// want to support compaction
rb_gc_mark_movable(foo->obj_one);
rb_gc_mark_movable(foo->obj_two);
}
Note that if the struct doesn’t have anything to mark (i.e. it doesn’t contain any Ruby objects), then we can set this function to NULL in the rb_data_type_t.
dfree
This function is called when the TypedData object is determined to be dead by the garbage collector and is about to be reclaimed. This is the function we use to free all resources (e.g. allocated memory, open file descriptors, etc.) that has been allocated for this object. Make sure this function frees all allocated sources, otherwise they will leak and may cause problems for the system (e.g. memory leaks causing the system to run out of memory)!
At the end of this function, make sure to also free the pointer passed in with xfree. xfree comes from Ruby itself since it may be using a different implementation of malloc than the one in the C extension.
// Defining the free function
static void foo_free(void *ptr)
{
foo_t *foo = (foo_t *)ptr;
// Free any resources we've allocated
free(foo->my_buffer);
// At the end, make sure to free the struct
// Make sure to use xfree and not free
xfree(ptr);
}
If the free function does not need to release any memory (except the call to xfree at the end), then we can use RUBY_DEFAULT_FREE in the rb_data_type_t instead of defining a function. Just some syntactic sugar Ruby’s C API provides.
dsize
This function is optional, so we don’t have to define it (pass in NULL in the rb_data_type_t if we don’t want to define it), but it’s good practice to define it. This function returns the memory usage (in bytes) of this TypedData object. If we don’t define this method, it will return only the size of the slot for the object (usually 40 bytes).
This function is useful for developers who are trying to determine the approximate memory usage of an object and especially useful for those that are profiling their application to find the source of memory bloat and ways to decrease memory usage. This function is called to get the memsize attribute returned by the ObjectSpce.dump method.
// Example defining the memsize function
static size_t foo_memsize(const void *ptr)
{
foo_t *foo = (foo_t *)ptr;
// Make sure to include the size of the struct in the memsize
return sizeof(foo_t) + foo->buffer_size;
}
dcompact
This function is only necessary if we want to support compaction (make sure to use rb_gc_mark_movable in the dmark function for objects we want to be movable). This function is called every time compaction is completed to update references for objects that may have moved.
To get the new address of a particular object, use rb_gc_location with the address of the object. This function will return the new address of the object. Make sure to call this on every object that may be moved, otherwise we may end up having broken Ruby objects.
rb_gc_location takes in one argument and returns the new address of the object:
ptr: The original pointer of the object.
// Function prototype for rb_gc_location
VALUE rb_gc_location(VALUE value);
// Example defining the compact function
static void foo_compact(void *ptr)
{
foo_t *foo = (foo_t *)ptr;
// Update the address for obj_one and obj_two because
// they may have moved
foo->obj_one = rb_gc_location(foo->obj_one);
foo->obj_two = rb_gc_location(foo->obj_two);
}
Conclusion
That was a long article, wasn’t it! TypedData objects are probably the most tricky part of Ruby’s C API. In this article, we looked at what TypedData objects are, how to create them, and how to configure them using rb_data_type_t. In the next article, we’ll look at how to raise errors, rescue from errors, and wrap functions in ensure blocks.